Bootstrap,Bagging,Boosting都属于集成学习方法,所谓集成学习方法,就是将训练的学习器集成在一起,原理来源于PAC (Probably Approximately Correct,可能近似正确学习模型)。在PAC学习模型中,若存在一个多项式级的学习算法来识别一组概念,并且识别正确率很高,那么这组概念是强可学习的;而如果学习算法识别一组概念的正确率仅比随机猜测略好,那么这组概念是弱可学习的。他们提出了弱学习算法与强学习算法的等价性问题,即是否可以将弱学习算法提升成强学习算法。如果两者等价,那么在学习概念时,只要找到一个比随机猜测略好的弱学习算法,就可以将其提升为强学习算法,而不必直接去找通常情况下很难获得的强学习算法。Bagging和Boosting都是Bootstraping思想的应用。
集成学习是指将若干弱分类器组合之后产生一个强分类器。弱分类器(weak learner)指那些分类准确率只稍好于随机猜测的分类器(error rate < 50%)。
一. Bootstrap
Bootstrap适用于数据集较小的情况。Bootstrap名字来自成语“pull up by your own bootstraps”,意思是依靠你自己的资源,称为自助法,它是一种有放回的抽样方法,它是非参数统计中一种重要的估计统计量方差进而进行区间估计的统计方法。其核心思想是从原样本集有放回的抽取N个子集,训练N个分类器,进行集成。
还有一种方发叫做Jackknife,和上面要介绍的Bootstrap功能类似,只是有一点细节不一样,即每次从样本中抽样时候只是去除几个样本(而不是抽样),就像小刀一样割去一部分。
而Bagging和Boosting都是Bootstraping思想的应用。
二. Bagging
Bagging是Bootstrap Aggregating的缩写,是一种用来提高学习算法准确度的方法,这种方法通过构造一个预测函数系列(一系列分类边界),然后以一定的方式将它们组合成一个预测函数(最终分类边界)。
Bagging是一种在原始数据集上通过有放回抽样重新选出S个新数据集来训练分类器的集成技术。也就是说这些新数据集是允许重复的。使用训练出来的分类器集合来对新样本进行分类,然后用多数投票(在一系列分类边界的中属于哪一类多就最终判定属于哪一类)或者对输出求均值的方法统计所有分类器的分类结果,结果最高的类别即为最终标签。
算法步骤:
1.从数据集S中取样(放回选样),总共执行t次
2.针对每一次取样训练得到分类模型,最终得到$t$个模型$H_1$…$H_t$
3.对未知样本X分类时,每个模型都得出一个分类结果,得票最高的即为未知样本X的分类
4.也可通过得票的平均值用于连续值的预测
当然还有一些更先进的Bagging方法,比如随机森林(random forest)
三. Boosting
Boosting是增强算法的意思,也就是由弱分类器转变为强分类器的过程。Boosting算法中主要是AdaBoost(Adaptive Boosting,自适应增强算法)。
根据维基百科介绍,AdaBoost是一种机器学习方法,由Yoav Freund和Robert Schapire提出。AdaBoost方法的自适应在于:前一个分类器分错的样本会被用来训练下一个分类器。AdaBoost方法对于噪声数据和异常数据很敏感。但在一些问题中,AdaBoost方法相对于大多数其它学习算法而言,不会很容易出现过拟合现象。AdaBoost方法中使用的分类器可能很弱(比如出现很大错误率),但只要它的分类效果比随机好一点(比如两类问题分类错误率略小于0.5),就能够改善最终得到的模型。而错误率高于随机分类器的弱分类器也是有用的,因为在最终得到的多个分类器的线性组合中,可以给它们赋予负系数,同样也能提升分类效果。
AdaBoost是一种迭代算法。每轮迭代中会在训练集上产生一个新的分类器,然后使用该分类器对所有样本进行分类,以评估每个样本的重要性(informative)。 具体来说,算法会为每个训练样本赋予一个权值。每次用训练完的新分类器标注各个样本,若某个样本点已被分类正确,则将其权值降低;若样本点未被正确分类,则提高其权值。权值越高的样本在下一次训练中所占的比重越大,也就是说越难区分的样本在训练过程中会变得越来越重要。 整个迭代过程直到错误率足够小或达到一定次数为止。
AdaBoost算法原理图如下:
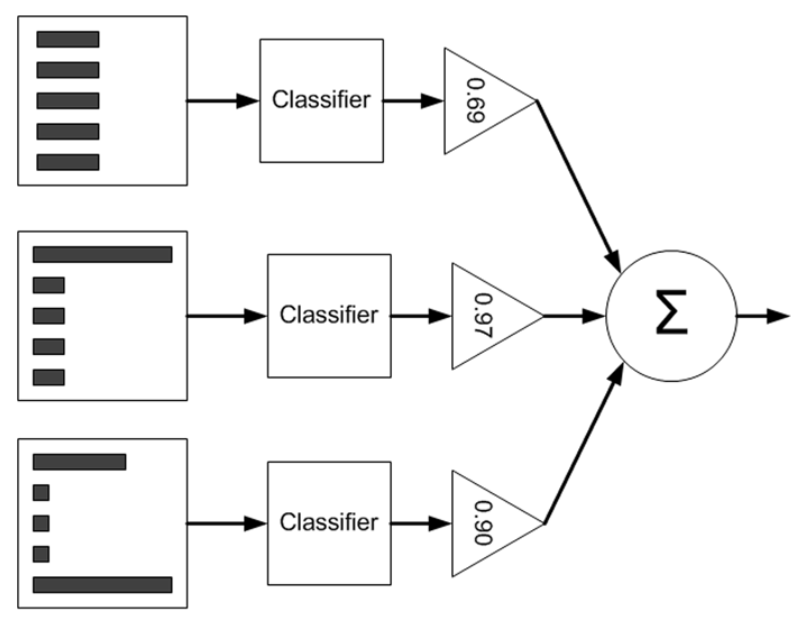
左边是数据集,其中直方图的不同长度代表样本的不同权重,第三列的三角形代表分类器的权值$\alpha$(计算方法见AdaBoost训练过程),单个分类器的输出会与该值相乘。AdaBoost最终结果为所有分类器输出的加权平均。
AdaBoost训练过程:
(1)为每个样本初始化权值$w^{(1)}=\frac{1}{n}$;开始迭代,在第$t$轮迭代中:
(2)使用训练集训练分类器$C_t$,并计算该分类器的错误率:
(3)计算分类器的权值为
(4)更新样本当前的权值wt.若分类正确,则减少权值:
若分类错误,则加大权值:
(5)迭代结束的标志可以是训练错误率为一个可接受的小数值,或者弱分类器数目达到指定值。
AdaBoost分类过程:
用生成的所有分类器预测未知样本X,最终结果为所有分类器输出的加权平均。
AdaBoost优点 :
(1)是一种有很高精度的分类器
(2)可以使用各种方法构建子分类器,Adaboost算法提供的是框架
(3)当使用简单分类器时,计算出的结果是可以理解的,并且弱分类器的构造极其简单
(4)简单,不用做特征筛选
(5)不容易发生overfitting。
AdaBoost缺点:
(1)对outlier(离群值)比较敏感
(2)训练时间过长,执行效果依赖于弱分类器的选择