个人认为深度学习的第一层基础知识是基本的神经网络知识,学习参数的方法(寻优,如梯度下降法,注意一下,BP算法是求偏导数的一种办法,属于梯度下降迭代中的一个步骤)。
个人认为深度学习的第二层基础是卷积神经网络,也就是CNN。CNN是一种网络结构,由多层网络组成,这其中有卷积层(Convolution)、池化层(Pooling)、ReLU、Dropout,有的网络可能没有Dropout,有的网络可能链接上以及结构上有更多的花样。现在就只说这四种。
一. 卷积层
为什么会出现卷积层,因为神经网络在处理图像是数据量太大,3通道图片的数据大小就是横纵像素的积再乘以3,神经网络训练本来就慢,这么多数据如果不想想如果减少数据肯定是不合理的。通过卷积核对原始数据进行卷积操作可以减少数据量,但基本上不损失特征,而且能让原始数据不那么特别,例如,同样两支玫瑰花,角度不同,在计算机眼里它们很不同,网络一层又一层,目的就是获取数据的语义信息。
卷积核对图片进行卷积操作就得到的卷积层的输出,卷积核的大小是人为设定的,比如可以设置成$3\times 3$或其他尺寸,卷积核的个数也是人为设定,太多太少都不合适,卷积核的内容是训练的时候学习得来的,学习方法一般也是梯度下降法,BP那一套。
卷积操作,其实就是卷积核在输入的二维数据面上每次移动一个步长,进行乘法运算再除以卷积核的元素个数,请看下面的gif和卷积运算示意图。
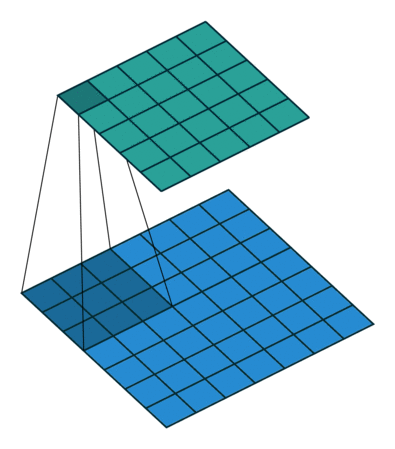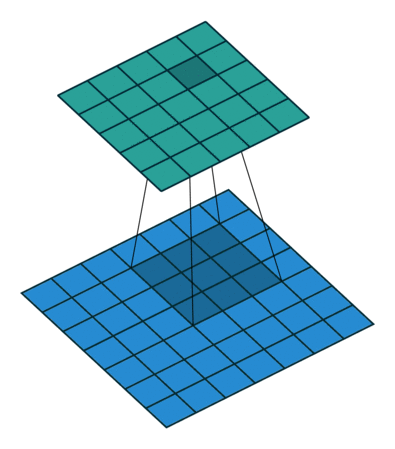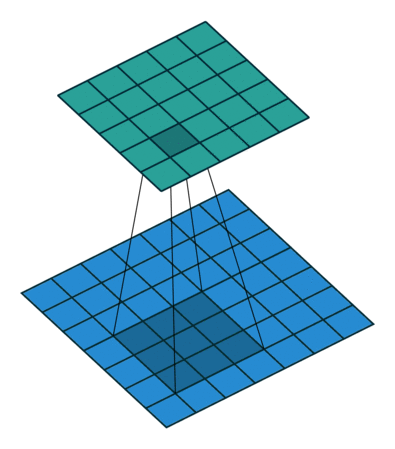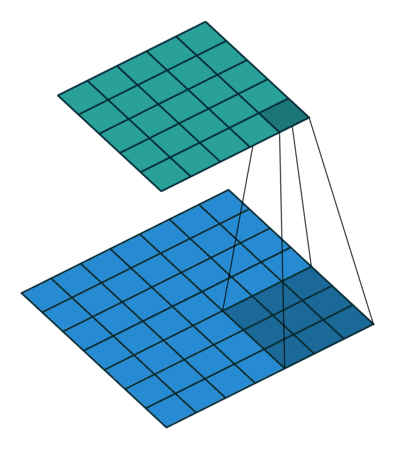
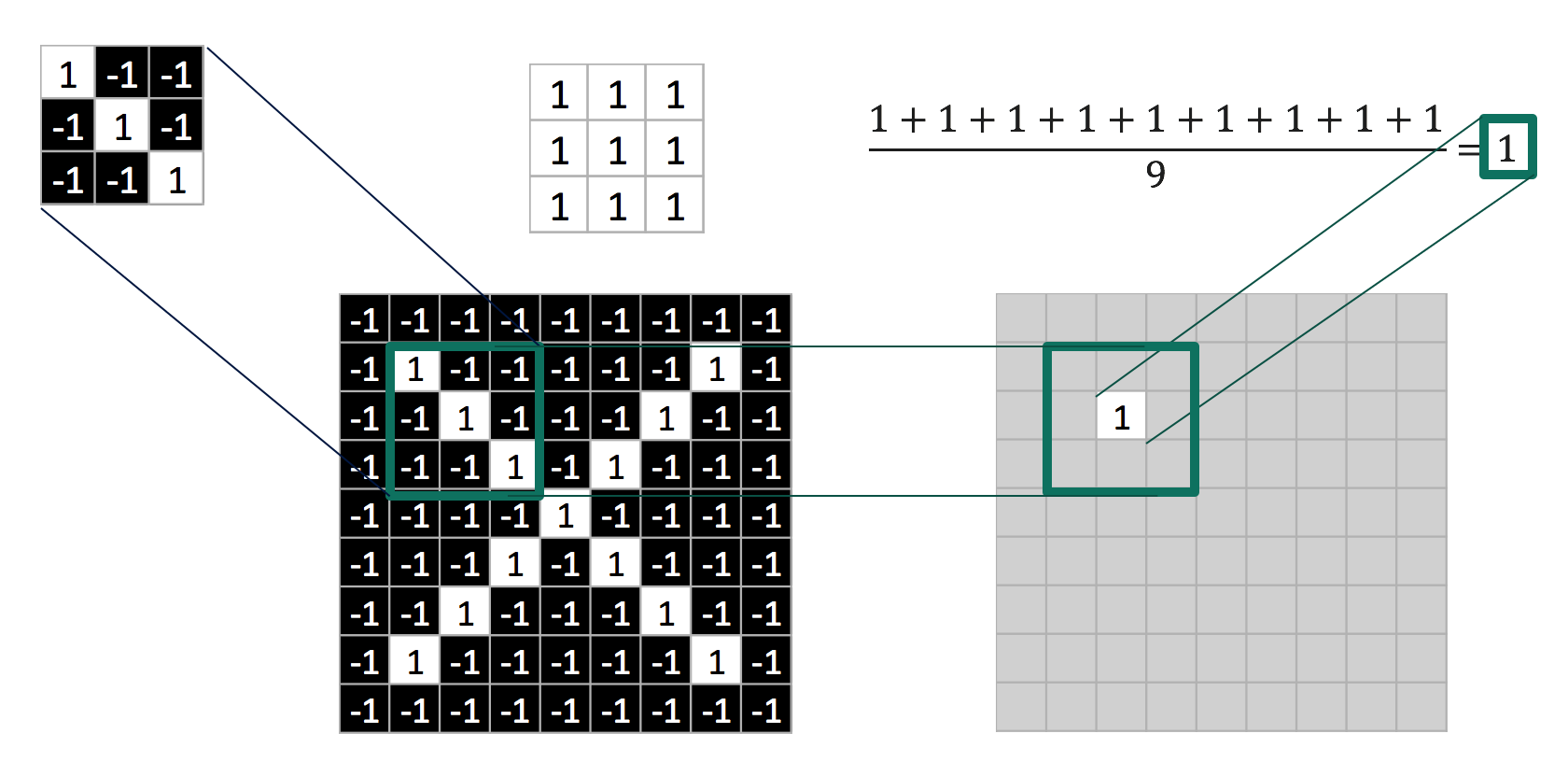
卷积操作结束后的输出如下图所示:
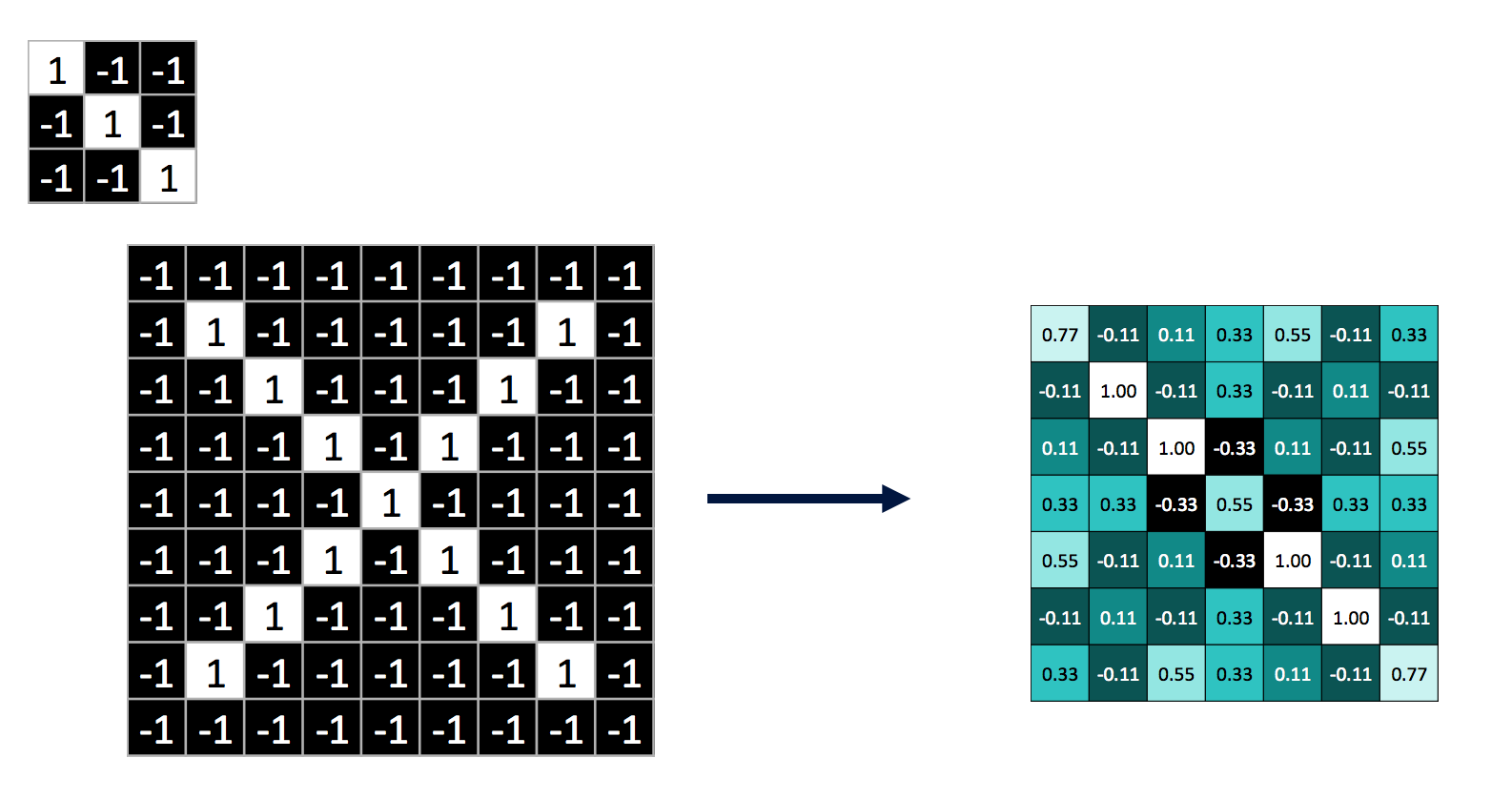
卷积运算的步长一般是1,这是因为过大的步长可能会遗漏部分特征。
二. 池化层
卷积操作减少了一部分数据量,但实际上数据量依然很大,这个时候出现了池化。个人感觉池化就好比一种成倍缩放二维数据平面尺寸的操作,池化单元的大小一般是$2\times 2$或者$3\times 3$,池化的步长与单元大小保持一致,也就是说池化的过程中不会像卷积那样有重叠的部分,对于数据的height和width如果不能整除池化单元,一般采用零填充(zero padding)的办法。常用的池化是最大值池化,具体操作如下图所示:
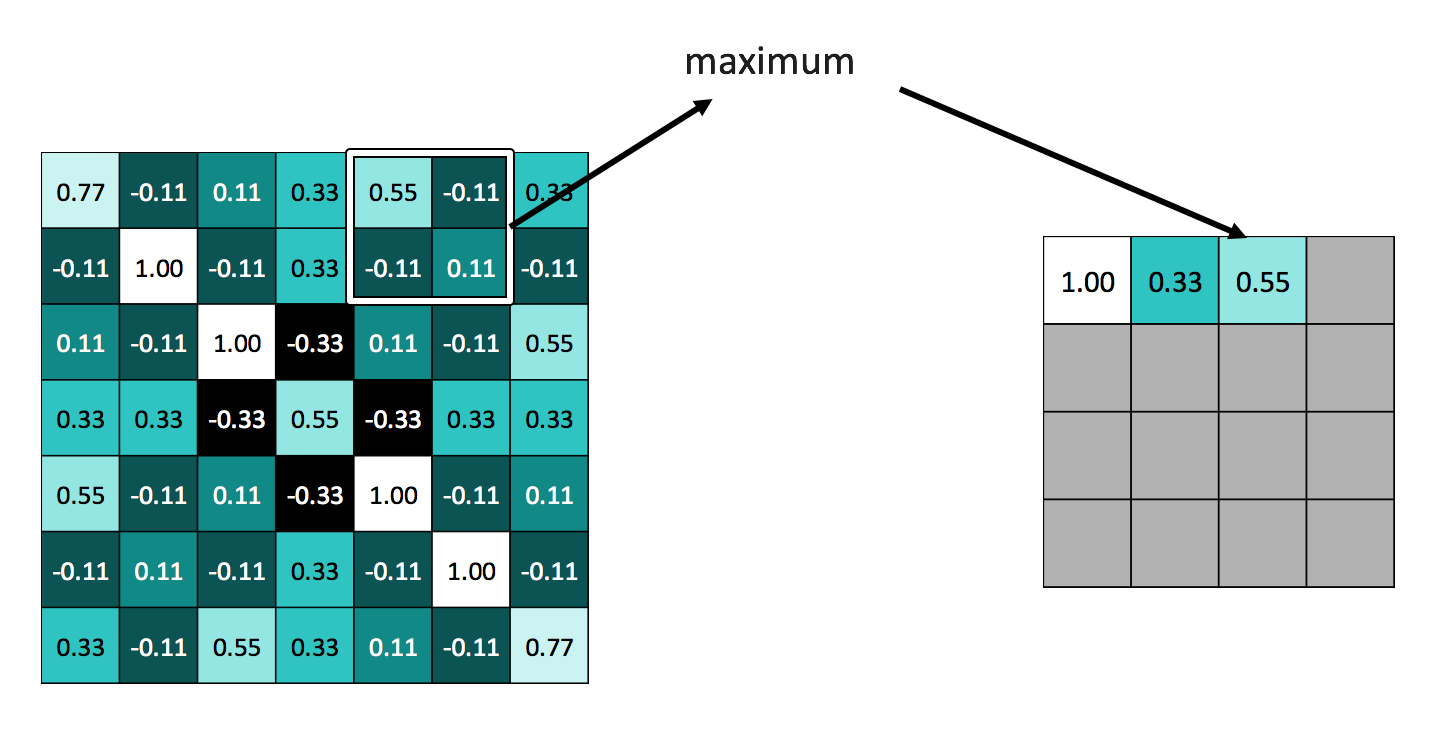
池化除了减少了数据量,还有另外一个意义:池化可以提高网络对目标微小旋转的识别鲁棒性,你仔细想一下,把一个图案已中心为原点进行微小旋转后,它的池化结果很可能和原始图案进行池化的结果一致或者差不太多。
三. ReLU
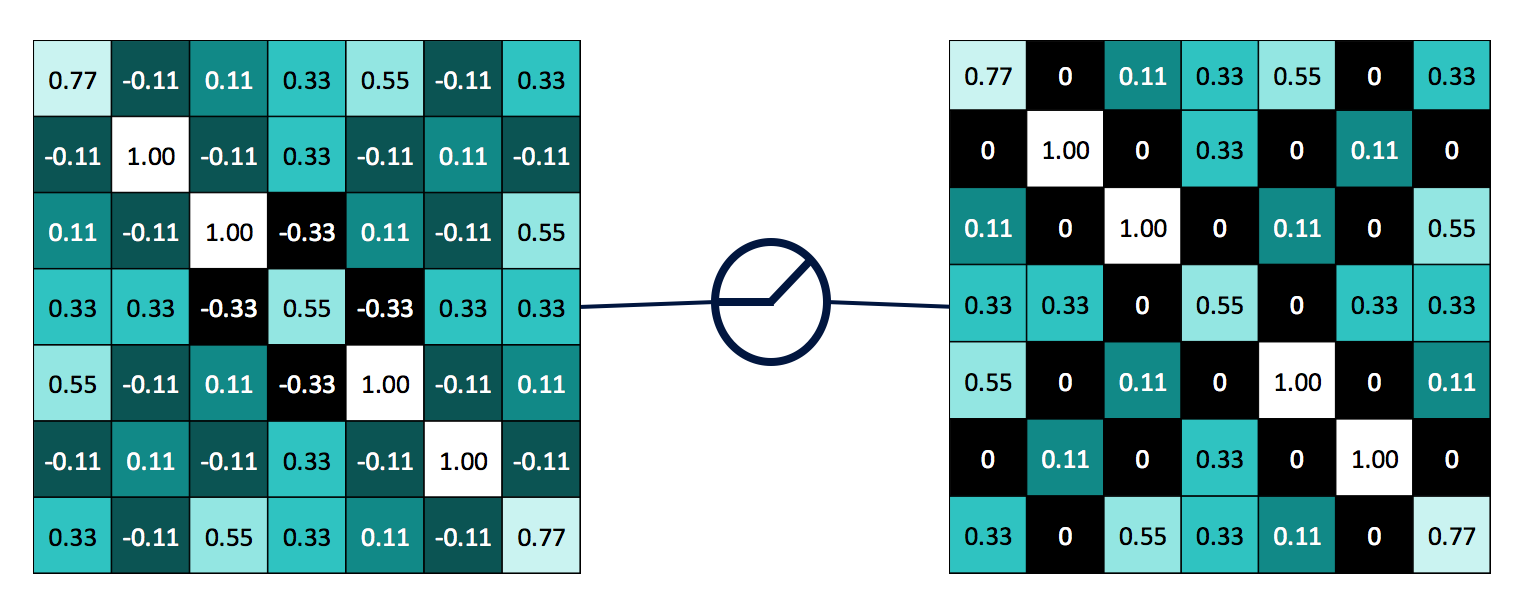
ReLU的全称是Rectified Linear Units,修正线性单元,一般在图示里都像是一个阀的样子,这在一定程度也就解释了ReLU的作用,想当是一种非线性限制操作,和我们学习神经网络时的sigmoid和tanh激活函数挺像的,其实ReLU的作用也和这些激活函数类似,就是使神经网络变得更有广泛性而不是单纯的线形组合,倘若没有非线性限制,那么不论中间有多少层隐含网络,输出都是输入的线性组合,相当于中间的网络没有任何作用。那么ReLU是怎样的非线性操作呢,其实比S函数等激活函数要简单的多,就是将一部分数值变为0,一般是把小于0的数全换为0,如下图所示:
ReLU在卷积神经网络中出现有很多原因,知乎作者Begin Again有个回答归纳得很好:
第一,采用sigmoid等函数,算激活函数时(指数运算),计算量大,反向传播求误差梯度时,求导涉及除法,计算量相对大,而采用Relu激活函数,整个过程的计算量节省很多。
第二,对于深层网络,sigmoid函数反向传播时,很容易就会出现梯度消失的情况(在sigmoid接近饱和区时,变换太缓慢,导数趋于0,这种情况会造成信息丢失,从而无法完成深层网络的训练。
第三,Relu会使一部分神经元的输出为0,这样就造成了网络的稀疏性,并且减少了参数的相互依存关系,缓解了过拟合问题的发生(以及一些人的生物解释balabala)。
四. 全连接(FC,Fully Connected Layer)
全连接很好理解,经过卷积、池化、ReLU后的数据输出形式是二维的数据,全连接就是将其向量化,然后连接隐含层或者直接连到输出层,这其实就和普通的多层神经网络差不多了,不做过多解释。
全连接层的参数是通过梯度下降求得,还是BP那一套。
五. Dropout
Dropout就是防止过拟合的一种策略,Dropout在训练的时候有,但在测试的时候是不能有Dropout的,毕竟只有在训练学习的时候才才担心过拟合。
简单讲,Dropout就是在按梯度下降法求网络参数的时候,每一次迭代都随机删掉一些隐含神经元,注意删掉之后会再次放回,下次迭代继续在所有隐含神经元存在的情况下随机删除。
解决过拟合的方法还有在代价函数添加正则项的方法,L1是添加绝对值,L2是添加二次方差。这两个正则项在数学上是可以证明的,能防止参数w过大。
那Dropout为什么有助于防止过拟合呢?可以简单地这样解释(该部分引自这个网址),运用了dropout的训练过程,相当于训练了很多个只有半数隐层单元的神经网络(后面简称为“半数网络”),每一个这样的半数网络,都可以给出一个分类结果,这些结果有的是正确的,有的是错误的。随着训练的进行,大部分半数网络都可以给出正确的分类结果,那么少数的错误分类结果就不会对最终结果造成大的影响。
实际上dropout不一定非要在全连接层隐含层,卷积似乎也可以dropout。
六.关于局部感知与权值共享
为啥CNN能应用到图像识别,相比多层感知器减少了很多数据量?靠的就是局部感知和权值共享。
局部感知依靠的是图片的局部相关性,所谓局部相关,就是你判断图片中某个物体的属性时,起关键作用的是物体邻近的小片像素区域,而距离较远的像素相关性较弱。试想一下,有一只猫在图片的左边,现在我们把图片右边区域全部删掉,此时你依然可以判断出图片内的物体是猫。不仅仅图片具有局部相关性,声音和文本也有,因此我们也经常看到CNN应用到声音和文本领域。
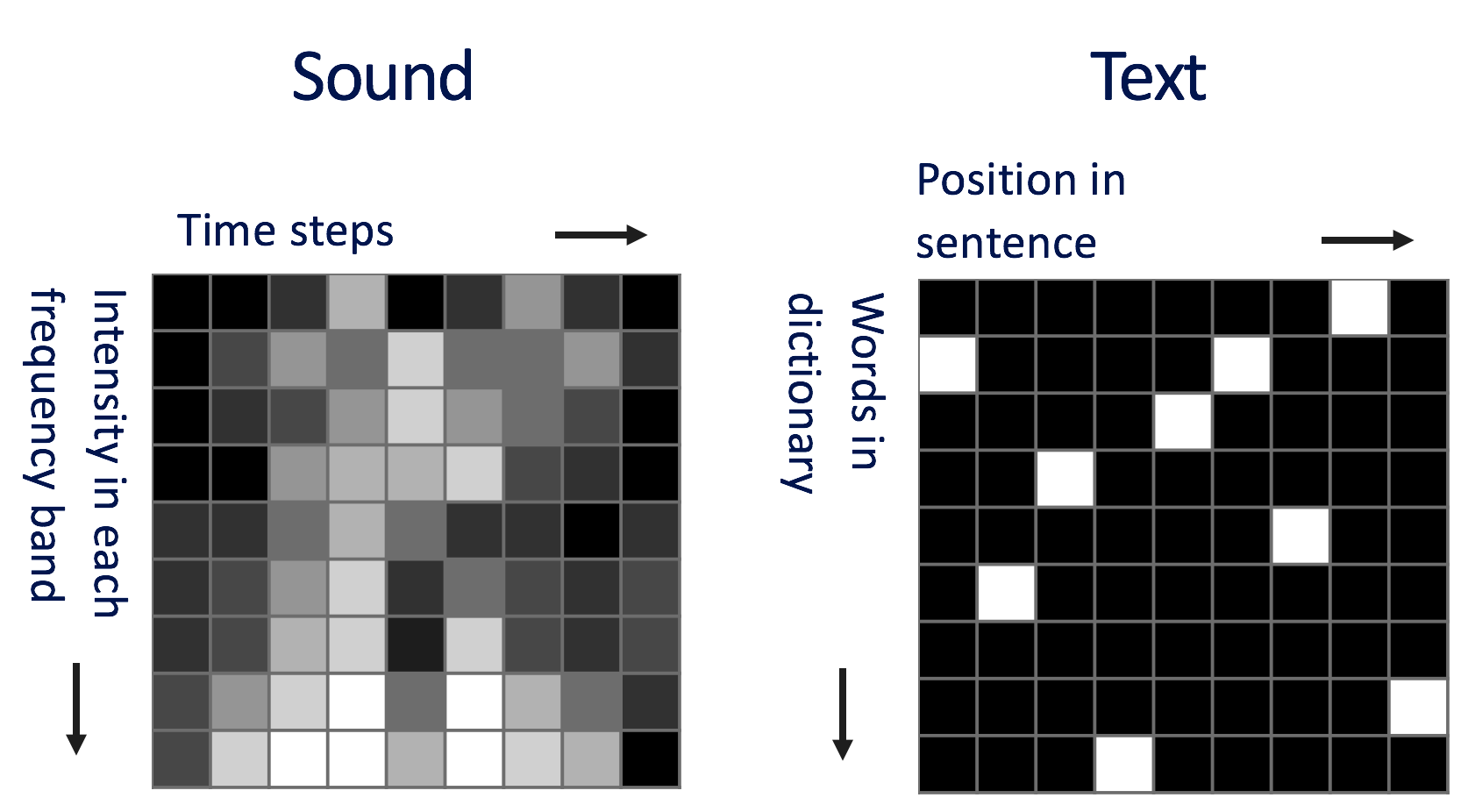
而权值共享就是一个卷积核(filter)扫描了整张图片,扫的过程中卷积核的权值是不会变化的。