Softmax回归,我们可以说它是逻辑回归的在多分类问题下的推广,我们也可以说逻辑回归是Softmax回归的一种特殊形式。
顾名思义,softmax函数不会像max函数那么严格,它会以概率的形式输出测试样本属于各个类别的概率,这些所有概率的和为1,也就是说我们可以将概率最大的值作为正确的分类结果,我们甚至可以按需求找出最可能的两类、三类等等。
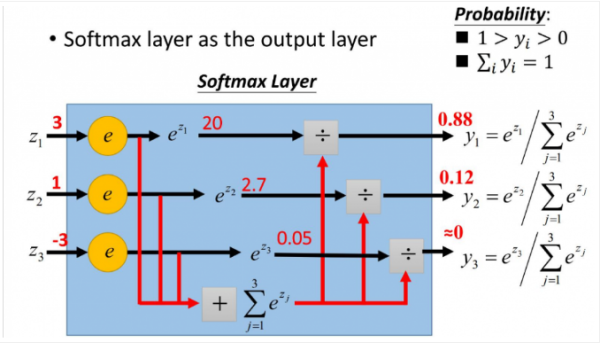
softmax在神经网络里往往为作为输出层,并且softmax的loss为交叉熵,选择交叉熵的原因是交叉熵在的偏导形式会非常简单,计算出偏导在通过bp进一步计算各层的偏导,然后梯度下降跌代得到合适的参数解。
一. 假设函数
在 softmax回归中,我们解决的是多分类问题(相对于 logistic 回归解决的二分类问题),类标 $y$ 可以取 $k$ 个不同的值(而不是 2 个)。因此,对于训练集 ${ (x^{(1)}, y^{(1)}), \ldots, (x^{(m)}, y^{(m)}) }$,我们有 $y^{(i)} \in {1, 2, \ldots, k}$。(注意此处的类别下标从 1 开始,而不是 0)。例如,在 MNIST 数字识别任务中,我们有 $k=10$ 个不同的类别。
对于给定的测试输入 $x$,我们想用假设函数针对每一个类别j估算出概率值 $p(y=j | x)$。也就是说,我们想估计 $x$ 的每一种分类结果出现的概率。因此,我们的假设函数将要输出一个 $k$ 维的向量(向量元素的和为1)来表示这 $k$ 个估计的概率值。 具体地说,我们的假设函数 $h_{\theta}(x)$ 形式如下:
其中 $\theta_1, \theta_2, \ldots, \theta_k \in \Re^{n+1} $是模型的参数。请注意 $\frac{1}{ \sum_{j=1}^{k}{e^{ \theta_j^T x^{(i)} }} }$ 这一项对概率分布进行归一化,使得所有概率之和为 1 。
二. 代价函数
代价函数如下:
这里1{.}是示性函数,其取值规则为$1{值为真的表达式 }=1$;$1{值为假的表达式 }=0$。权重衰减项 $\frac{\lambda}{2} \sum_{i=1}^k \sum_{j=0}^{n} \theta_{ij}^2$ 来修改代价函数,这个衰减项会惩罚过大的参数值。
有了这个权重衰减项以后 ($\lambda > 0$),代价函数就变成了严格的凸函数,这样就可以保证得到唯一的解了。 此时的 Hessian矩阵变为可逆矩阵,并且因为$J(\theta)$是凸函数,梯度下降法和 L-BFGS 等算法可以保证收敛到全局最优解。
为了使用优化算法,我们需要求得这个新函数 $J(\theta)$ 的导数,如下:
$\nabla_{\theta_j} J(\theta)$ 本身是一个向量,它的第 $l$ 个元素 $\frac{\partial J(\theta)}{\partial \theta_{jl}}$ 是 $ J(\theta)$对$\theta_j$ 的第 $l$ 个分量的偏导数,通过最小化 $J(\theta)$,我们就能实现一个可用的 softmax 回归模型。